


Data profiling demystified: the unsung data quality hero 🦸
Why over half of your project time hinges on mastering this skill

Have you ever started an analysis or machine learning project without knowing which dataset to use? Or the dataset was given, but you had no idea which attributes to use or the difference between the three attributes that seem to mean the same? You’re not alone.
More than 50 percent of a data science project is spent on data preparation.
I couldn’t find a recent survey, but many sources claim that data preparation takes 40 to 80 percent of a data science or analytics project. Why does gathering, understanding, and cleaning the data to be used in a dashboard or machine learning model take that much time? We can blame the documentation, the data platform team, or whoever we want, but the reality is that we don’t use the same data source in the same way for multiple projects. A slight change in the objectives, and you have new considerations and constraints.
Much of that time can be reduced with data profiling. In this post, I will define what it is, its benefits, and what techniques you can use. I will also explain when it’s a good moment to do it, why, and what tools are available for successful data profiling.
What is it and why should I care? 🤷🏼♂️
Data profiling is a process that systematically analyzes and reviews a dataset to gain a deeper understanding of its structure, content, relationships, and overall quality, by producing valuable and actionable summaries and reports.
Data profiling is the essence of data understanding.
During the data profiling process, you will apply analytical and statistical methods to understand the data at the table and column levels and the relationship between columns and other tables.
Therefore, it is an essential skill to master in all data-related roles, from data engineers, data analysts, data scientists, and machine learning engineers. Why?
Data Engineer: Needs to understand the structure to join different datasets, and the data quality to create tests and metrics.
Data Analyst: Data structure is critical, and understanding relationships between attributes or the overall data quality will help decide which dataset or attribute to use for the analysis.
Data Scientist and ML Engineer: Content and relationships in the data are crucial for building and maintaining models. Data quality could affect the model’s performance and will impact its predictions.
Apart from those role-specific needs, there are many benefits:
Discovery. It helps you discover the available attributes and data types. People make tables and data services, and sometimes the names and data types are not the best. It is also crucial when using third-party data because even if you have documentation, you must ensure accuracy and usability.
Prioritization. You can decide what attribute to use among others or which data quality initiative needs to be started first to correct the most critical assets.
Documentation and catalog. Since it’s a systematic process, you can document your findings, improve the general understanding and nuances of the analyzed datasets, and include that information in a central repository or catalog. That will help the team and stakeholders know about the data assets.
“Better outcomes”. I will discuss why I don’t think data profiling leads to improvements by itself, but all the information and understanding gathered during the process will have a positive impact on the related data products when used (and used correctly).
Risk identification. When data is used for decision-making, having a better understanding of content and quality is crucial to identify potential risks when using the result of an analysis or machine learning model prediction. You can prevent anomalies or imbalanced data from reaching a machine-learning model.
Contracts. It’s a hot topic these days, but by understanding the structure and content, you can create data contracts to enforce the expected structure and improve communication between producers and consumers. I discussed about that in one of my previous posts.
Differences with related concepts 🔗
Data profiling is central to many other data related activities, but let’s define its boundaries and how it relates to them.
Data analysis. The purpose of data analysis is to get insights and information about processes or entities represented by the data, such as customers or sales. Data profiling is to get information and knowledge about the data itself. For example, when you’re profiling personal information, it doesn’t matter if they are customers or employees, because they will almost have the same data (like email, phone number, etc).
Data mining. While data profiling focuses on understanding the data and its characteristics, data mining is the process of discovering patterns, correlations, and trends by analyzing the data. Data profiling also involves checking correlations, but data mining goes deeper, applying more advanced techniques.
Data preparation. Data preparation involves other concepts like data cleansing, integration and transformation. It’s related with data profiling because you get to understand what needs to be cleaned and transformed, and how a dataset relates to other assets. In data preparation you always do some kind of transformation or addition to the data, but in data profiling you only analyze and understand what is given without changing its structure and content.
Data quality assessment. This might be the trickiest one, because data quality is tightly related with data profiling. Data quality assessment involves defining the rules and evaluating if a dataset meet the quality standards required for business purposes, and data profiling is evaluating and analyzing the data itself, not taking the business rules into consideration, or any context that would “explain” if something is okay or not. For example, data profiling will output the percentage of nulls in a column, and the data quality assessment will determine if that is valid for the business or not.
You can think about data profiling as the process of data quality requirements gathering. The first step to get an overview of the data quality that allows you to ask more specific questions, investigate further, and start defining rules and metrics.
Data profiling techniques 🔍
There are several types of data profiling techniques, each addressing specific aspects of the analysis:
Column profiling. Focuses on individual columns of a dataset, and computes statistics and metadata to understand the distribution and characteristics of each column. Examples: minimum and maximum values, average, median, null count, unique values and count, and data types.
Cross-column profiling. Reveals relationships and dependencies among columns within the same table. Can identify correlations, overlaps, and redundancies across columns. It can be used to discover or validate primary keys.
Cross-table profiling. Identifies relations between columns in different tables or datasets. It can be used to identify foreign key relationships, overlapping and redundancies, and plays an important role in data integration.
Duplicate analysis. Searches for duplicate records using all the available columns or the table primary keys. It’s very important for data integration or reporting, to prevent errors while joining different datasets.
Other techniques. Pattern analysis (correct format), frequency distribution (count of different groups or categories), data rule validation (simple business rules or integrity checks), and cardinality check (one-to-one and one-to-many relationships between datasets).
These different techniques can be categorized in different groups:
Structure discovery. Focuses on the format of the data, ensuring it is consistent throughout the dataset. It uses techniques like column profiling and pattern analysis. Example: email address has a valid format.
Content discovery. Assesses individual elements of the dataset looking for errors. It identifies ambiguities, incomplete or null values, and inconsistencies. Techniques like data rule validation and column profiling are applied in this context. Example: address is missing the street number.
Relationship discovery. Searches for connections and associations among data sources, and how they are related. It could be the relationship between different datasets or references inside the same table. It uses techniques like cross-column profiling and cross-table profiling. Example: column is a foreign key to another table.
How can I start with data profiling? 🤔
Data profiling is a widely used process to understand and improve data assets, but integrating that could be new to data practitioners. Before diving into the tools, here are some ideas about when to incorporate that process and which data roles are involved:
Before starting an analysis, feature engineering or data preparation. It will give you a better understanding of the available attributes and an overview of its data quality. It can help you to discard some attributes or look for other sources in order to improve or compliment the initial dataset. Roles: data analyst, data scientist.
Before data transformation and integration. If you are working with raw data, you might need to understand unique values, identify outliers and foreign keys to perform the right integration. If you have a set of standard values for a column, you can identify the unique values in the sources to map to the expected values. Roles: data engineer, data scientist.
During data pipeline development and after deployment. It can help to check consistency and structure of assets generated, and understand if changes in data sources are affecting the processing, or that needs to be updated. Roles: data engineer.
Report and dashboard development. It will help identifying the right data sources, check consistency and completeness, and validate relationships for joins. Profiling is crucial throughout the process to check the data sources and results generated. Roles: data analyst.
Available tools 🛠️
This is my favorite section of the post, because you get to know what you can use, applying all the concepts I introduced in the previous sections.
Data landscape is evolving all the time. Some tools were great, but are not being maintained, so I will start with plain SQL and present a couple of stablished tools everyone can use (I normally go with open-source when available).
SQL queries
This is a common approach that can be applied in any DBMS. Instead of going through all the different query types you can easily get a list of them by asking ChatGPT. You can ask it particular queries and more nuanced analysis, but you can start as easy as follows:
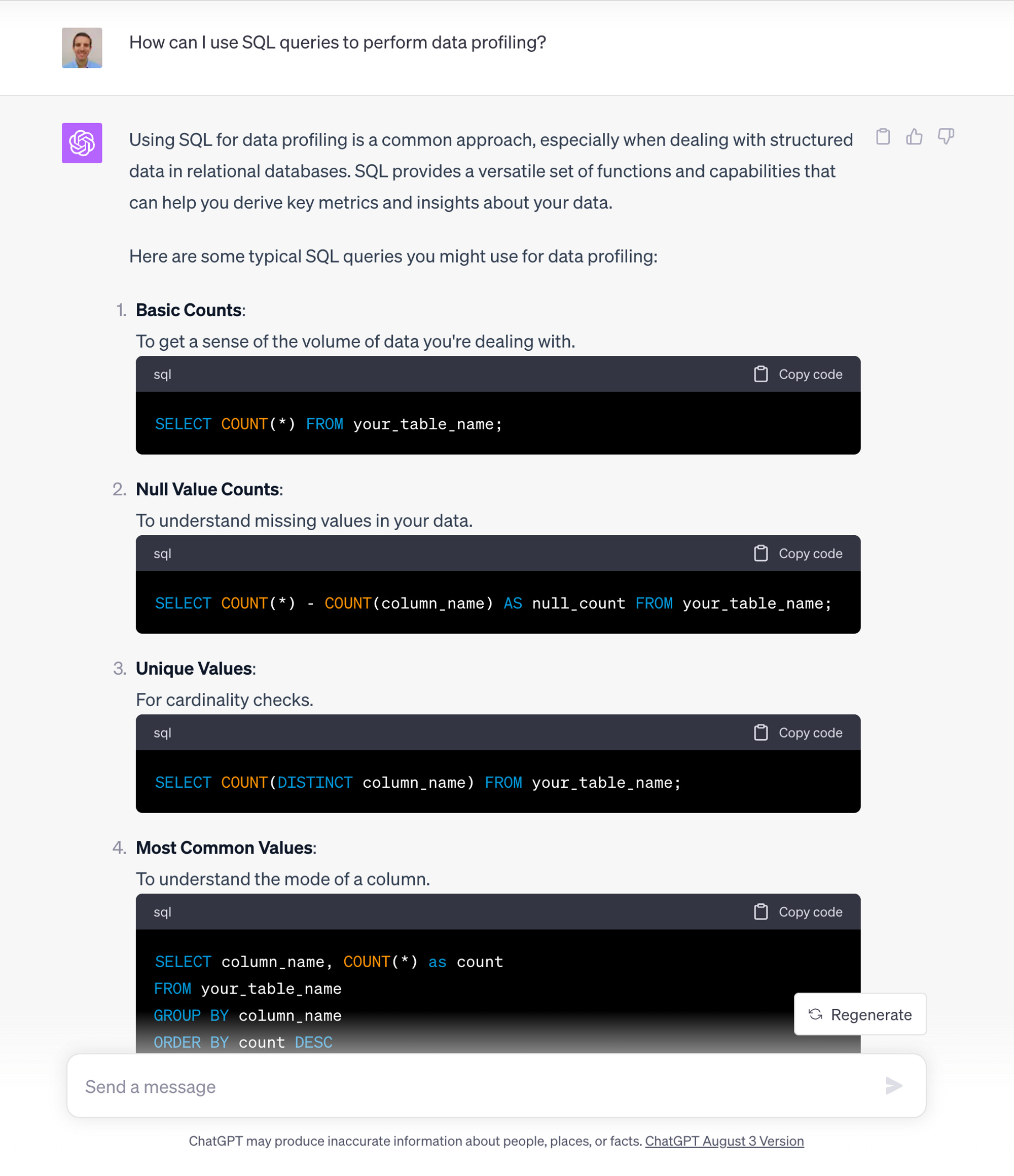
I won’t be adding much value pasting the queries here, so you can start with my prompt and ask follow up questions if you want something else.
ydata-profiling
ydata-profiling (previously known as pandas-profiling), provides a one-line exploratory data analysis (EDA), delivering an extended analysis of a DataFrame. It was previously limited to pandas DataFrames, but they recently introduced support for Spark DataFrames profiling.
Main features:
Data types inference: Automatically detect columns data types.
Alerts summary: List of the main problems in the data that you might need to work on. You can find a list with the available alerts in the documentation. It includes: constant, imbalance, skewness, missing values, duplicates and empty.
Univariate analysis: Descriptive statistics (min, max, mean, median) and visualizations such as distribution histograms.
Multivariate analysis: Includes correlations, detailed analysis of missing data, duplicate rows, and visual support for variables pairwise interaction (correlation heatmap and table).
Datasets comparison: One-line solution to enable a complete report on the comparison of datasets (not available for Spark). You can check more details in the documentation.
Flexible output formats: Analysis can be exported to an HTML report that can be easily shared, as JSON for easy integration in automated systems, and as a widget in a Jupyter Notebook. You can also customize the report appearance.
Integration: Can be integrated in interactive data applications like Streamlit (more details and examples in the documentation). Another amazing integration is with Great Expectations (sadly, it is no longer supported). It can generate an
ExpectationSuitewhich contains a set of Expectations based on the profiling. Check the details in the documentation.
It’s really easy to integrate it in a Jupyter Notebook with a few lines:
import numpy as np
import pandas as pd
from ydata_profiling import ProfileReport
df = pd.DataFrame(
np.random.rand(100, 4),
columns=["a", "b", "c", "d"],
)
# Generate the standard report
profile = ProfileReport(df, title="Report")
profile.to_notebook_iframe()
If you want to navigate the report structure and test the features described above, you can check Census Income or Titanic examples. You can even launch a Colab notebook directly from here.
Rill’s auto-profiler
I didn’t have this on my radar until I watched Building a SQL editor around “fast” – DuckCon a couple of days ago.
Rill allows you to model data and create fast, exploratory dashboards. It’s powered by DuckDB and the speed to perform data profiling is incredible.
It is way more than a data profiling tool, but I wanted to include it because I was amazed by the performance and design principles. Some of them include:
Focus on UX. Powered by Sveltekit and DuckDB, it returns results in a matter of seconds.
Local and remote datasets. Imports and exports Parquet and CSV (S3, GCS, HTTPS, local).
Automatic profiling. Helps you build intuition about your dataset through automatic profiling, so you don’t have another data analysis “side-quest”.
No "run query" button. Responds to each keystroke by re-profiling the resulting dataset.
Interactive dashboards. Interactive dashboard defaults to help you quickly derive insights from your data.
Dashboards as code. Each step from data to dashboard has versioning, Git sharing, and easy project rehydration.
I tried it locally and works perfect. You can easily get started with an example project using the following commands:
curl -s <https://cdn.rilldata.com/install.sh> | bash
git clone <https://github.com/rilldata/rill-examples.git>
cd rill-examples/rill-openrtb-prog-ads
rill start
Here’s a short GIF demonstrating some features: Rill features.
Conclusion
Data profiling plays an important role in data quality as the process of data quality requirements gathering. We reviewed the benefits, why it’s important across different roles in data, and when we can implement it to improve our data products results.
Finally, I have presented three ways of doing data profiling at scale. I hope this helps you and your team to incorporate this valuable technique in your daily workflow. See you in the next one!