
Untangling data chaos: a guide to open-source data quality tools
A comparative analysis of Great Expectations and Soda Core

In my first article, I wrote about why data quality matters and argued about the importance of data quality. Everything can be summarized with “garbage in, garbage out” and how caring and improving data quality will lead to better decisions and outcomes.
I didn’t answer one question on purpose. How can you improve data quality?
There are known unknowns. That is to say, there are things that we know we don't know. Donald Rumsfeld
The answer doesn’t fit in one article, but everything starts with testing. One of your “known unknowns” is the quality of your data, and you can leverage data quality tools to tackle the first stage of data quality improvement.
There are plenty of tools and many articles describing their features, Gartner reports, and the excellent MAD (ML/AI/Data) landscape that has a special section for “Data Quality & Observability” (it’s a great starting point if you’re looking for options)

In this article, I want to focus on open-source tools you can integrate into the so-called “modern data stack”. Why open-source? It’s more a philosophical than a technical question, and I’m aware in many cases, it’s better to pay for a great tool that will have a huge ROI (saving engineering costs as well), but I like the combination of community-driven development and low-entry barrier to start using without having an up-front cost.
The tools
As I mentioned, many tools are out there, but sadly, there are few options in the open-source ecosystem. You can “force” some of the tools to enter the podium, but from my perspective, there are only two general-purpose open-source tools for data quality: Great Expectations and Soda Core.
Let me know if you want another article about the “other tools” I disregarded and why, but I did it mainly because they’re platform-specific or not maintained. Please leave me your thoughts in the comments.
About the selected tools, I have hands-on experience with both, integrating them into our data pipelines. Both have their nuances, and none of them covered 100% of our use cases, but they’re mature tools you can use in production workloads without question.
Let’s do a quick overview, and then I will review each tool's different aspects and features. I will focus on the definition of data quality metrics. You can comment if you want me to dig deeper into other features.
Great Expectations:
Python library (retired CLI since April 2023)
Allows you to define assertions about your data (named expectations)
Provides a declarative language for describing constraints (Python + JSON)
Provides expectations gallery with 300+ pre-defined assertions (50+ core)
A long list of integrations, including data catalogs, data integration tools, data sources (files, in-memory, SQL databases), orchestrators, and notebooks
Runs data validation using Checkpoints
Subject matter expert friendly for expectations definition using data assistant
Automatically generates documentation to display validation results (HTML)
No official docker image
Cloud version available
Great community regarding contributions (GitHub), knowledge exchange and Q&A (Slack)
Soda Core:
CLI tool and Python library
Allows you to define assertions about your data (named checks)
Provides a human-readable, domain-specific language for data reliability called Soda Checks Language (YAML)
Includes 25+ built-in metrics, plus the ability to create user-defined checks (SQL queries)
Compatible with 20+ data sources (files, in-memory, SQL databases)
Runs data validation using scans
Display scan results in the CLI (save to file available) or access them programmatically
Collects usage statistics (you can opt out)
Docker image available
Cloud version available
Decent community regarding contributions (GitHub), knowledge exchange and Q&A (Slack)
Now that the overview is done let’s dive into some aspects I consider important:
Data source integration
Available assertions
Custom assertions (extensibility)
Validation execution
Bonus: GitHub statistics
Data source integration
When you’re looking for a data quality tool, you want to be able to use it in different contexts, especially with various data sources.
Both tools provide a reasonable set of compatible data sources, including the more prominent data warehouse solutions (Snowflake, BigQuery, Redshift), SQL OLTP databases (PostgreSQL, MySQL, MS SQL Server), query engines (Athena, Trino), and text files (through Pandas).
Great Expectations has a longer list of compatible data sources, but I don’t think it makes a huge difference (it does, in case the data source you use is not listed).
Check the complete list from Great Expectations and Soda Core.
Available assertions
An assertion is a statement about your data, something you expect to be true, and you need to check to assess the quality of your data.
Again, both tools provide a set of predefined expectations/checks that you can test against attributes in your data source. Most common: validate missing counts, row counts, schema validation, regex match, reference check, and numeric metrics (min, max).
If you look at the numbers, you may think Great Expectations is way beyond Soda Core, but it’s not an apples-to-apples comparison.
For Great Expectations, an expectation is an assertion about the data, and you could need many of them to define a data quality metric. On the other hand, Soda Core combines metrics and thresholds to define a check.
Example: NULL count check
Let’s see a simple example of a NULL count check on a column, starting with the assertion “column_to_check shouldn’t have NULL values”.
Great Expectations:
validator.expect_column_values_to_not_be_null("column_to_check")
Soda Core:
checks for table_to_check:
- missing_count(column_to_check) = 0
But what if now I realized I want to consider “NA” as NULL as well?
Great Expectations:
validator.expect_column_values_to_not_be_null("column_to_check")
validator.expect_column_values_to_not_be_in_set("column_to_check", ["NA"])
Soda Core:
checks for table_to_check:
- missing_count(column_to_check) = 0:
missing values: [NA]
In SodaCL (Soda Checks Language), you use the same metric and threshold and add a column config. In Great Expectations, you need to add another expectation. The conclusion is that you cannot compare the expectations number with the metrics number because conceptually they are different things.
You need to understand the logic behind each paradigm and define your metrics based on your needs.
Custom assertions
Your business, your rules.
Both tools provide an extensive list of assertions, but depending on your needs, you must define your own custom assertions. The paradigm is slightly different, so creating custom assertions involves different steps.
Great Expectations (documentation):
Choose between creating private expectations or contribute to the open source project
Understand the different expectation classes
Code the Python class that implements the metric and validation
Once defined it can be used anywhere
Example: here
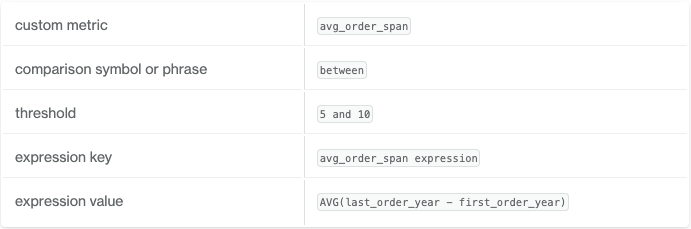
Soda Core (documentation):
Use common table expressions (CTE) or SQL queries (a file can be referenced)
Defined for a specific table
Example:
checks for dim_reseller:
- avg_order_span between 5 and 10:
avg_order_span expression: AVG(last_order_year - first_order_year)
Validation execution
Both tools provide a CLI and programmatic way to run validations. In Great Expectations they call them Checkpoints, and the most common way to run them is programmatically. In Soda Core you run a scan that executes checks, and the most common way to run it is using the CLI.
As I mentioned before, Great Expectations retired their CLI, but you can still use it to run checkpoints. Soda Core allows you to run programmatic scans using Python, providing an API to access logs and results.
You can execute the validations using your local environment, but the idea is to integrate them into an orchestration tool that could run them without your assistance, leaving the results in a repository or database. Documentation available for Soda Core and under integrations for Great Expectations.
GitHub statistics
Given they’re open-source tools, it’s worth checking GitHub statistics. Great Expectations is more community driven and has way more activity than Soda Core.
The statistics were collected on August 3, 2023.

https://github-stats.com/great-expectations/great_expectations
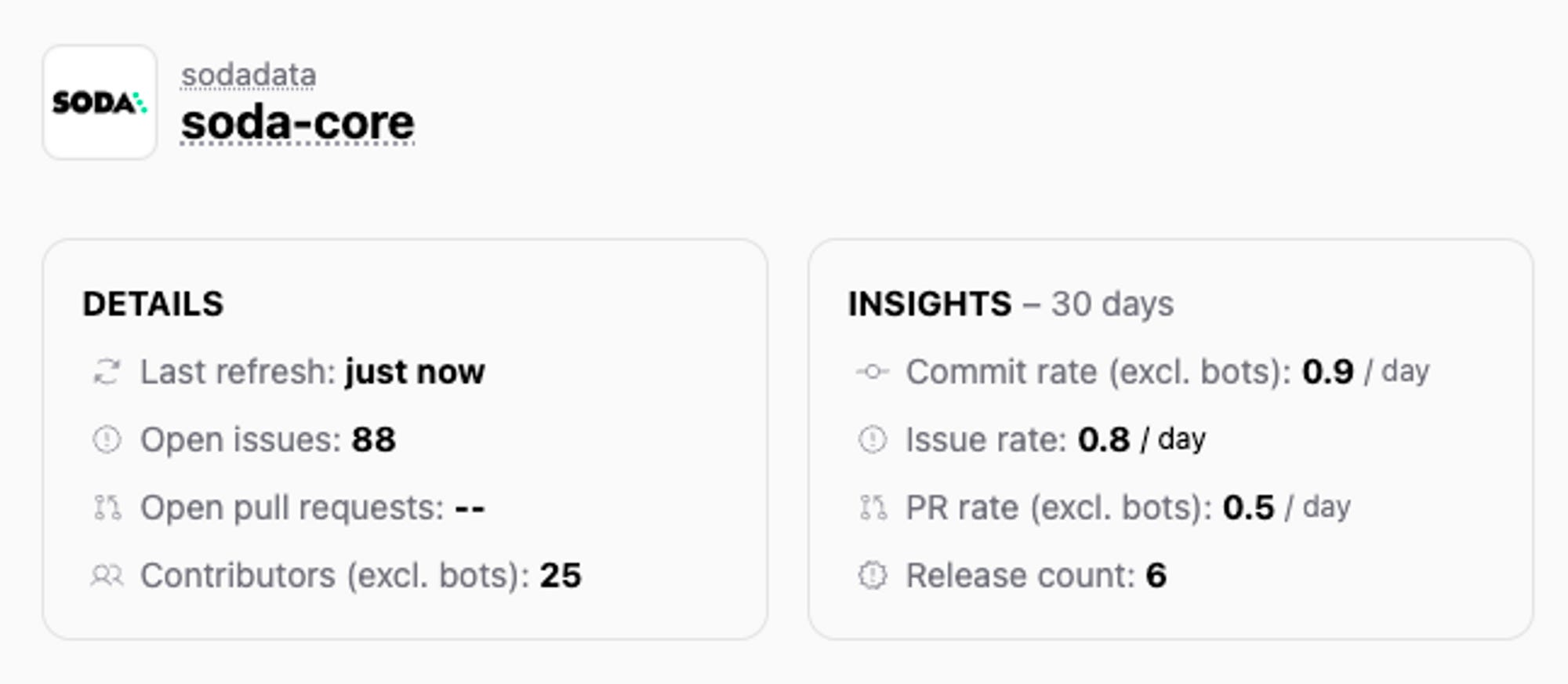
https://github-stats.com/sodadata/soda-core
Conclusions
As with any tool, you need to understand your use cases to see if they fit your needs and the gaps. As I mentioned, we used both in my current job for different use cases, and you need to do the homework to figure that out.
Let me do a quick summary of the aspects we analyzed.
Great Expectations:
Bigger community and contributions
Extensive list integrations with data sources and tools
The open-source version is incredibly complete
A lot of Python code (I love it, but it could be a difficulty) that could be alleviated using data assistant
Programmatic validations are preferred
Steep learning curve to extend
Soda Core:
Most common data source integrations available
Easier to define assertions in
YAMLformatSodaCL is complete and powerful
Execute validations with CLI is preferred
SQL code for custom assertions
Both have their wins and nuances, so if you want me to continue analyzing these tools, consider subscribing and leave a comment with what you want to read next.